Assumedly there are non-programmers, or at least users who may need a refresher on how to code in C++ as well as some small points they may have never covered in their programming experience. This section presents a basic refresher/introduction to some of the programming methods that are used in the Open-Sessame Framework.
int x; // defines an integer double z; // defines a double (double-precision float) float w, r; // defines two floats, not great programming practice int ii = 0; // defines and initializes an integer
Sometimes, in functions that are called very often, it is useful to define a variable as static. Much of the overhead in computation is allocating and deallocating memory for temporary variables. A static variable has its memory allocated the first time it is called, and the memory is set aside for the variable for the duration of the program. This can greatly speed up operation, as small functions that use large numbers of variables (such as matrices and vectors) must allocate the memory, do a simple computation, and then release the memory. By making the variable static, this allocation and deallocation must only happen once, and subsequent operations are performed in the same memory address.
static double myArray[10];
For example, there is a Car class which stores the speed of the car in "Miles Per Hour" (MPH). There is an operation, much like a function, we can call that gives us the speed, GetSpeedMPH(), which returns the speed in miles. However, it is later decided that the speed should internally be stored as Kilometers Per Hour (KPH). The class operation GetSpeedMPH() is internally changed to convert the internal mileage from KPH to MPH, however, an user of the Car class doesn't need to know about this internal change, since the user still calls GetSpeedMPH() and gets the speed of the car in MPH.
Terminology
vector<Car> myCarCollection;
To call member functions of a class, a '.' is used between the instance of the class and the member function call:
Car myCar; myCar.SetSpeedMPH(55); // set the speed of my car to 55 MPH cout << myCar.GetSpeedKPH(); // output the speed of the car in KPH to the console
Inheritance is how protected member functions and data members are used. There may be functionality that derived classes should be able to use from a base class, but outside users of the class don't need access to. Continuing the car example, the Car class has a function SetMileage() that all cars have, but shouldn't be accessible by an outside user of the class. However, derived classes, such as SportsCar or StationWagon may need to be able to set the mileage based on their use. Again private member functions and data members are not accessible to derived classes, only to the class in which they are instantiated.
An example may help illustrate this point. The user could implement a Vehicle abstract data type. This is object-oriented because the user may want to define a general interface to all vehicles, such as Move() Stop(), or even Location(). However, there really isn't anything that is a vehicle. I can't go to a rental agency and say, "I want to rent a vehicle". I have to choose if I want a car, a bicycle, or roller skates. However, all of these vehicles have the common functionality of moving, stopping, or having a location. So instead of worrying if all of the classes have the functionality implemented, or what it's called I can define the functions and name and then make sure (or the code won't compile) each of the derived classes implement these functions.
int myInt = 5; int myOtherInt; myOtherInt = myInt; myInt = 2; cout << myInt << " != " << myOtherInt; // outputs 2 != 5
int myInt = 5; int* myPointerInt; myPointerInt = &myInt; // the & is used to return a reference, or the memory address of myInt myInt = 2; cout << myInt << " = " << *myPointerInt; // outputs 2 = 2, the * is required to 'dereference' the pointer // and make it act as a normal variable
However, the user should be cautioned when using pointers. The user is interacting with the computer's memory which is usually how segmentation faults and other bad things happen (by referencing unitialized memory, NULL pointers (pointers to 0x0), or the wrong memory address). Another problem is by leaving memory around that is not being used or referenced to. This is commonly known as a memory leak. Refer to your local programming manual for more information.
int* pMyInt = new int; // allocate memory (of size int) *pMyInt = 5; // Dereference the pointer (use memory space) and assign the value pMyInt = NULL; // Assign the pointer to NULL (0x0) - WARNING by doing this, we have 'lost' // the reference to the allocated int memory, which is now just hogging up // memory space. We should have called "delete pMyInt;" first.
The last 'point' on 'pointers' is how they affect classes and calling member functions. When dealing with a normal class instance, we used a '.' to call a member function. When using a pointer to an instance, instead of having to dereference the pointer, we can just use '->' to call the member functions:
Car* pMyCar = new Car; pMyCar->SetSpeedMPH(88.7); *pMyCar.GetSpeedKPH(); // this works the same, but isn't "nice" delete pMyCar; // remember to clean up
Furthermore, pass-by-reference allows the user to pass data back out of a function other than just by the return type. This works like pointers and is illustrated below:
int myFunction(int inputInt, double& _inputDouble) { _inputDouble = static_cast<double>(inputInt); // static_cast makes sure to change the // value from a type int to a type double return inputInt * 5; } void main() { double mainDouble = 0; cout << myFunction(5, mainDouble); // outputs '25' cout << mainDouble; // outputs '5' }
When the user doesn't need to change the variable in a function, it is still better to pass-by-reference. To make sure the variable isn't changed unexpectedly, the variable can be defined const.
int myFunction(const int& inputInt, double& _inputDouble) { _inputDouble = static_cast<double>(inputInt); return inputInt * 5; }
int myFunc1(const int& inputVar); // just a prototype, but it is defined elsewhere int myFunc2(const int& inputVar); int (*intFuncPtr)(int); // definition of the function pointer void main() { intFuncPtr = &myFunc1; // Assign the function pointer to the first function cout << intFuncPtr(5); intFuncPtr = &myFunc2; cout << intFuncPtr(5); // Same call as above, but now calls function 2 }
ObjectFunctor myObjFunc(myCar, &Car::GetSpeedMPH);
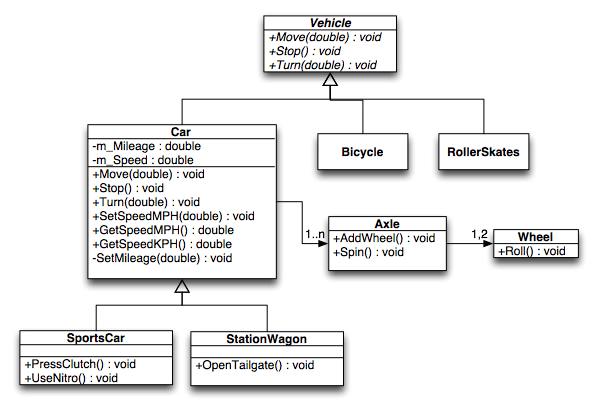
Shown below is an example UML class diagram describing the example classes of vehicles and cars described above.
Inheritance is shown using open arrows in the middle of lines between classes. The arrow points towards the base class. Therefore, Car is derived from Vehicle. Also note that Vehicle is in italics, which means that it is abstract (ADT). Futhermore, the member functions are in italics denoting that they are pure virtual.
Lastly, aggregation, or composition of classes, is shown using diamonds and arrows. This is saying that the class with the diamond "has-a" class where the arrow points to. Furthermore, the number of instances are shown with the numbers (1..n being atleast 1 up to any number, or "1,2" denoting 1 or 2 elements). From the example, a Car can have 1 to however many Axles, which have 1 or 2 Wheels.
Other UML diagrams demonstrate "Use Cases", "State Diagrams", "Activity Diagrams", or "Event Traces". Refer to a UML book or style guide for more information.
 1.3
1.3